
Format Settings Reference for Universal API Connector

In general, Format Settings are used by workflow triggers to define how to handle and pre-process data that is fetched from a system. This setting is responsible for converting data from one format (such as csv or json) into Saltbox Message format (XML) so it can be processed by the workflow. Some Connectors apply a default Data Source Format automatically, while others require configuration. This depends on the Connector, and is outlined where appropriate below.
Refer to the details below.
Universal API Connector triggers utilize the following message formats:
| Message Format | Description | Version |
|---|---|---|
CSV with Parent and Related Data |
This Data Source Format supports CSV data which combines Parent and Child data into two sections within the same CSV file. See below for more details. |
2.10+ |
Universal API Converter - with split options |
Handle API data. Optionally split data using advanced settings. | 2.0+ |
Message Formats
CSV with Parent and Related Data
| Message Format | Description | Version |
|---|---|---|
CSV with Parent and Related Data |
This Data Source Format supports CSV data which combines Parent and Child data into two sections within the same CSV file. See below for more details. |
2.10+ |
This Data Source Format supports CSV data which combines “Parent” and “Child” data into two sections within the same CSV file. This is essentially two files in one where “parent” information is the first section, followed by a column name reset that defines the “child” information.
Depending on the system, parent information is sometimes called “header”, “document”, “parent” or “root” data, while the child information is sometimes called “details”, “lines”, “child” or “nested” data.
This Data Source Format takes the specified parent field and uses it to group together related child items. Each grouping is created as a distinct Saltbox message, which will be handed to the workflow for processing.
Settings for CSV Parent and Related Data
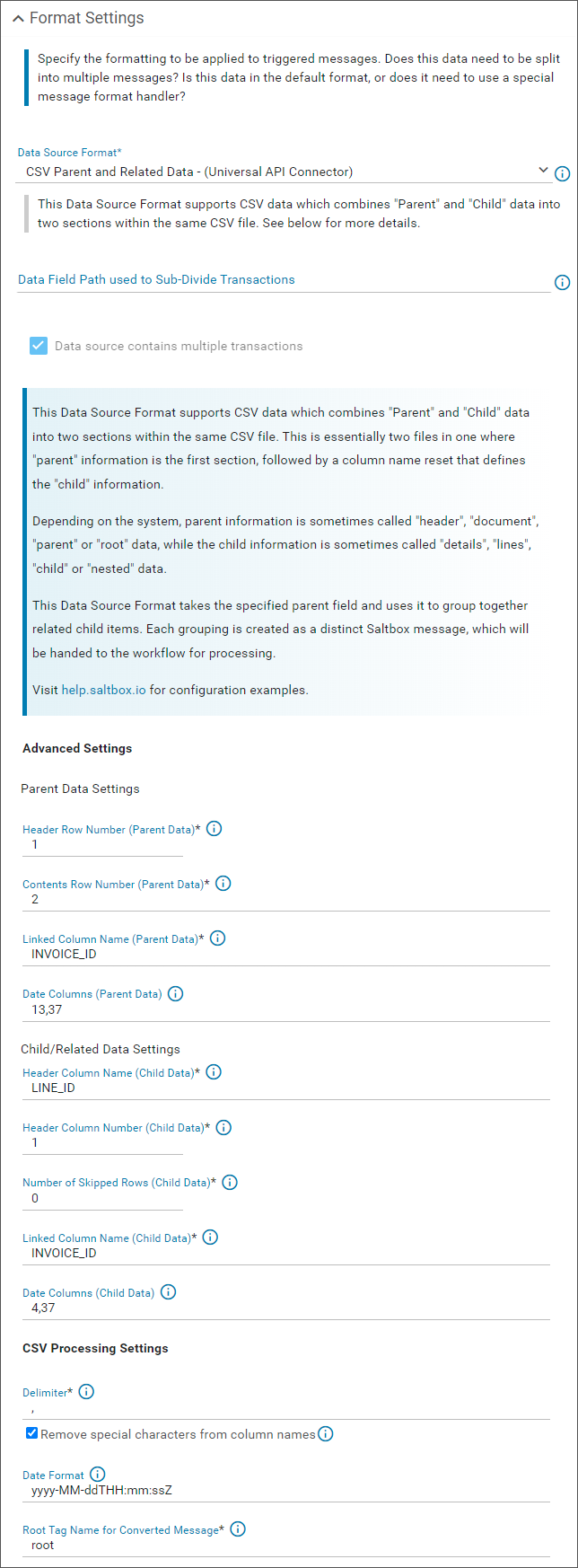
Parent Data Settings (CSV Parent and Related Data Format)
This section defines how the parent data section of the CSV file will be processed.
-
Header Row Number (Parent Data)(default: 1): Row number of the parent data header row. This option may be set if there are extra rows above the parent data header row. For example, if there is a prefix section, blank lines, or metadata at the top of the CSV file. If the data starts immediately, the first line is the default starting point. -
Contents Row Number (Parent Data)(default: 2): Row number of the first parent data element. If there are a known number of empty rows between the parent header row and the first parent data row, use this value to define where the data starts. -
Linked Column Name (Parent Data): Name of the parent column which will be linked to the child data. Data which matches the corresponding linked child column will be grouped together.This setting expects exactly one parent entry per child, but many children can belong to the same parent (i.e. parent entries must be unique but there may be many children for the same parent). If not, this action will fail.
This is commonly an ID.
-
Date Columns (Parent Data): Column numbers of any parent columns which contain a formatted date.ex: If the first, fifth and ninth columns contain dates, set this to: 1,5,9
Child/Related Data Settings (CSV Parent and Related Data Format)
This section defines how the child (or related) data section of the CSV file will be processed.
-
Header Column Name (Child Data): Name of the Header Column that will be used to identify when the data transitions from “parent” data to “child” data. It is expected that this name cannot be contained within the parent data column which shares the same CSV column.ex: If the Header Column Name is “INVOICE_ID”, there must be no parent data in the same column that contains this name as its data.
-
Header Column Number (Child Data)(default: 1): Column number that will be inspected for the Header Column Name (Child Data) specified above. -
Number of Skipped Rows (Child Data)(default: 0): The specified number of rows after the child header will be skipped when processing this data.ex: If there are a known number of empty rows between the child header row and the first child data row, configure this value to offset the data starting point. Otherwise, set this value to 0 (no offset).
-
Linked Column Name (Child Data): Name of the child column which will be linked to the parent data. Data which matches the corresponding linked parent column will be grouped together.This setting expects exactly one parent entry per child, but many children can belong to the same parent (i.e. parent entries must be unique but there may be many children for the same parent). If not, this action will fail.
This is commonly an ID.
-
Date Columns (Child Data): Column numbers of any child columns which contain a formatted date.ex - If the first, fifth and ninth columns contain dates, set this to: 1,5,9
CSV Processing Settings (CSV Parent and Related Data Format)
-
Delimiter(default: ,): This delimiter is used to split CSV data. -
Remove special characters from column names: Recommended to ensure special characters don’t result in malformed message data. May be disabled in specific technical scenarios. -
Date Format: Date format will be applied when processing date fields in either parent or child data. -
Root Tag Name for Converted Message: When this data is processed it will be converted into workflow message data. This tag name will be used to wrap parent and child data. Resulting data tree will contain the following data paths:-
/root/Header: defines the parent details. There is only one such data path. -
/root/Lines: defines the child details. Each child row is a separate/root/Linesdata element. There may be no child data elements, in which case this data path will not exist. There may be many child data elements, in which case they will be listed in the order in which they are encountered in the CSV file.
-
Example: CSV Parent and Related Data Format
Sample CSV data is noted below. Lines 1-8 define the “parent” and lines 9-24 define the “child” data. They are connected by a common INVOICE_ID which is the first column of the parent section, and the second column of the child section.
INVOICE_ID,CUSTOMER_NAME,TOTAL_DUE,INVOICE_DATE,,
8380199,Acme Co,343.95,2022-08-13,,
8380200,Ace Pilots Inc.,4221.96,2022-08-13,,
8380203,Acme Co,402.14,2022-08-14,,
8380208,Proton Corp.,1337.55,2022-08-14,,
8380215,Proton Corp.,1101.01,2022-08-15,,
8380224,Acme Co,392.22,2022-08-15,,
8380235,Ace Pilots Inc.,2847.22,2022-08-15,,
LINE_ID,INVOICE_ID,ITEM_NO,QTY,UNIT_PRICE,SUB_TOTAL
8380199-1,8380199,S00178,3,26.17,78.51
8380199-2,8380199,S00189,5,35.09,175.45
8380199-3,8380199,S00212,1,89.99,89.99
8380200-1,8380200,LW8873,4,1055.49,4221.96
8380203-1,8380203,S30021,14,9.36,131.04
8380203-2,8380203,S00189,4,35.09,140.36
8380203-3,8380203,LQB17,2,65.37,130.74
8380208-1,8380208,H904B,1,267.51,1337.55
8380215-1,8380215,S00937,5,63.18,315.9
8380215-2,8380215,H504Q,4,69.99,279.96
8380215-3,8380215,LW304B,5,101.03,505.15
8380224-1,8380224,LQB17,6,65.37,392.22
8380258-1,8380258,LW5041,3,400.67,1202.01
8380259-1,8380259,H50743,1,1101.01,1101.01
8380270-1,8380270,S00937,8,63.18,505.44
To process the above data, the following settings are used:
-
Parent Data Settings:
-
Header Row Number (Parent Data): 1 - The parent header starts on the first line. -
Contents Row Number (Parent Data): 2 - The parent data starts on the second line. -
Linked Column Name (Parent Data): INVOICE_ID - This unique identifier will be used to group related child data. -
Date Columns (Parent Data): 4 - The 4th column of the parent data is a date.
-
-
Child/Related Data Settings:
-
Header Column Name (Child Data): LINE_ID - The name of the column of the child header data that will be inspected. In this case, this header starts on line 9, and we’re inspecting column 1 “LINE_ID”. -
Header Column Number (Child Data): 1 - The column index of the column of the child header data that will be inspected. In this case, this header starts on line 9, and we’re inspecting column 1 “LINE_ID”. -
Number of Skipped Rows (Child Data): 0 - the child data starts immediately after the header. -
Linked Column Name (Child Data): INVOICE_ID - In this case, the linked column name is the same for both parent and child, but this does not need to be the case. -
Date Columns (Child Data): (empty) - There are no child columns which are dates.
-
-
CSV Processing Settings
-
Delimiter: , (comma) -
Remove special characters from column names: Enabled/Checked - Recommended for most use cases. -
Date Format: yyyy-MM-dd - Data format is applied to all identified child and parent Date Columns (in this case, only the parent data contains a date column). -
Root Tag Name for Converted Message: INVOICE - The message that’s generated is wrapped in this root tag.
-
Universal API Converter - with split options
| Message Format | Description | Version |
|---|---|---|
Universal API Converter - with split options |
Handle API data. Optionally split data using advanced settings. | 2.0+ |
Version 1 Message Formats
Version 1 of the Universal API supports the following message format (associated with version 1 workflow trigger). This is no longer available as of version 2. To update to version 2 or higher, install the new connector version and use the Universal API message formats listed in the previous section.
| Message Format | Description | Version |
|---|---|---|
Generic API Converter - with split options |
Handle API data. Optionally split data using advanced settings. | 1.0, 1.1 |
V1 Message Format Details
Generic API Converter - with split options
| Message Format | Description | Version |
|---|---|---|
Generic API Converter - with split options |
Handle API data. Optionally split data using advanced settings. | 1.0, 1.1 |